
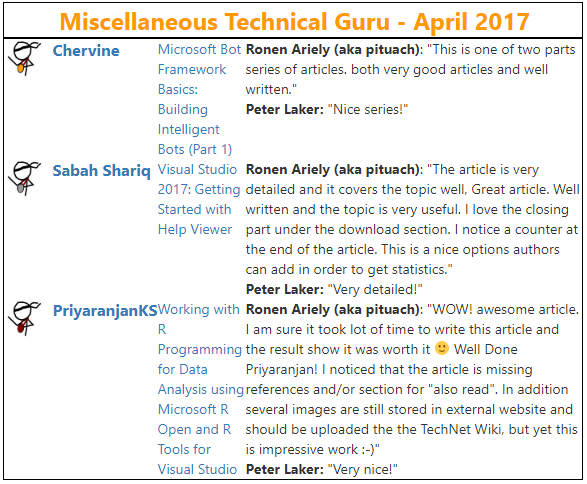
Query Unstructured Data From SQL Server Using PolyBase
Scope
The following article demonstrates how unstructured data and relational data can be queried, joined and processed in a single query using PolyBase, a new feature in SQL Server 2016.
Pre-Requisites
Introduction


Installing PolyBase
In this article, SQL Server 2016 RC0 is used and it is used in an Azure VM that is already pre-configured and can be provisioned at any time.

1. Ensure all the required software are installed:
- 64-bit SQL Server Evaluation edition
- An external data source, either Windows Azure blob storage, or a supported Hadoop version (see Choose a Hadoop version or Azure Blob storage using sp_configure ).
- Microsoft .NET Framework 4.0. Go to the download center
- Oracle Java SE RunTime Environment (JRE) version 7.51 or higher (64-bit). Go to downloads . The installer will fail if JRE is not present.
- Minimum memory: 4GB
- Minimum hard disk space: 2GB

2. Install PolyBase
Go to control panel > Add/Remove programs > Microsoft SQL Server 2016 and click on Uninstall/ change. Then click on Add and browse to the setup of SQL Server 2016 (64-bit).
On an Azure VM, the set-up is found at C:SQLServer_13.0_Full


3. Add PolyBase feature to the existing SQL Server installation


4. Verify installation
a. In services.msc, the 2 services below should be running.

b. Verify Polybase installation in SSMS
Run the following query to view the status of the PolyBase installation.
1 = Installed
0= Not installed

Configure PolyBase to connect with an existing Big Data Solution
1.Create a Master Key Encryption
The database master key is a symmetric key used to protect the private keys of certificates and asymmetric keys that are present in the database.
When it is created, the master key is encrypted by using the AES_256 algorithm and a user-supplied password.
2. Create a Database-Scoped Credential
The credential is used by the database to access to the external location anytime the database is performing an operation that requires access.
Identity= Storage Account Name
Secret = Storage Account Key
3. Reconfigure Hadoop Connectivity
Reconfigure updates the currently configured value (the config_value column in the sp_configure result set) of a configuration option changed with the sp_configure system stored procedure.
In this example, it will change the global configuration settings for PolyBase Hadoop and Azure blob storage connectivity.
Below are the connections that can be used at the time of writing:
o Option 0: Disable Hadoop connectivity
o Option 1: Hortonworks HDP 1.3 on Windows Server
o Option 1: Azure blob storage (WASB[S])
o Option 2: Hortonworks HDP 1.3 on Linux
o Option 3: Cloudera CDH 4.3 on Linux
o Option 4: Hortonworks HDP 2.0 on Windows Server
o Option 4: Azure blob storage (WASB[S])
o Option 5: Hortonworks HDP 2.0 on Linux
o Option 6: Cloudera 5.1, 5.2, 5.3, 5.4, and 5.5 on Linux
o Option 7: Hortonworks 2.1, 2.2, and 2.3 on Linux
o Option 7: Hortonworks 2.1, 2.2, and 2.3 on Windows Server
o Option 7: Azure blob storage (WASB[S])
In this example, since Azure Blob Storage is being used, option will be used.
The next step is to restart the MSSQLSERVER service. If this is not done, several errors will be encountered during the next steps.
When this service is being restarted, the PolyBase services will also be restarted.

4. Create an External Data Source
This defines from which source to fetch and process the data.
X= Hadoop cluster name
Z= Storage account name
5. Create a File Format
This is a prerequisite for creating the actual layout of the data in the external table and defines the structure of the file to be read.
PolyBase supports these file formats:
• Delimited text
• Hive RCFile, and
• Hive ORC
6. Test – load and query sample data from Azure Blog Storage

Example: Analyzing Application Logs
Assume someone has a business running and has been storing all his application logs.
Someday, the application got a severe error on one of the most critical areas and the management decides to contact all the customers that tries to access the Application at that time.
Since, the database down, the only way to track these customers were through the logs. But now, how to get the details of these customers?
This problem can be easily solved with PolyBase.
The following example demonstrates the analytics and BI capabilities of joining both the relational and unstructured data using PolyBase.
Relational Customer table
The following is a relational customer table where all the customer data are stored on-premise.

Application Logs on Azure Blob Store
The following is the raw dump of application logs stored on the Azure blob storage.

1. Create external table for the logs

2. View all customers that got an error on the EPayment Page and their contact details

3. Fetch the features that got more than 10 errors

4. Migrate data from the Blob storage to a relational table.

5. Transparent BI experience with both the unstructured and relational data using PowerBI Desktop.
a. Connect to SQL Server Database

b. Data can be imported both from the structured and external unstructured tables

c. Relationships can also be defined between the tables

d. Creates Dashboard using any of the data seamlessly

References
https://msdn.microsoft.com/en-us/library/mt143171.aspx
https://msdn.microsoft.com/en-us/library/mt163689.aspx
https://msdn.microsoft.com/en-us/library/ms174382.aspx
https://msdn.microsoft.com/en-us/library/mt270260.aspx
https://msdn.microsoft.com/en-us/library/mt143174.aspx
https://msdn.microsoft.com/en-us/library/dn935022.aspx

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}