Developing a Recommender Solution with Azure Machine Learning
While preparing my presentation for the Developer’s Conference on Machine Learning, I got the idea to make a demo of a recommender engine.
Ever wondered how websites like Amazon and Ebay provides you useful suggestions and recommendations? This blog post is for you!

Introduction
To have a complete introduction to Machine Learning in general and Azure Machine Learning, please read my previous blog post here.
Designing the Experiment
Below are the steps to develop the experiment:
1. Add the dataset
In AzureML, you may upload your existing dataset or load one from an Azure Database, Azure Blob Storage,Data Feed Reader, Web Service or a Hive Query.
In this example we shall add the Movie Ratings Sample Data.
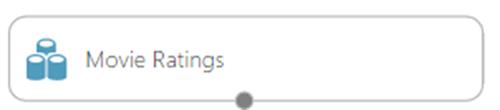
The Movie Rating sample has the following columns:
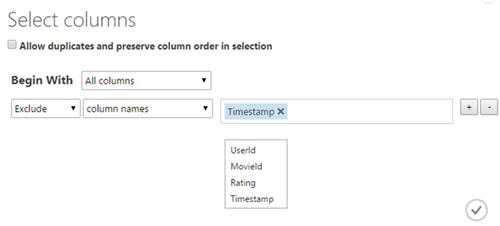
2. Exclude the columns that shall not be needed
To do so, the project columns tool object can be used. Add it in the experiment,
3. Split the data
We now need to partition the data into 2 distinct sets:
– Train Data : Used to “train” the recommender
– Test Data : Used to validate the results of the recommender
Drag the split tool and connect it as below.

Deciding about the amount of data to use for training and testing is is subjective.
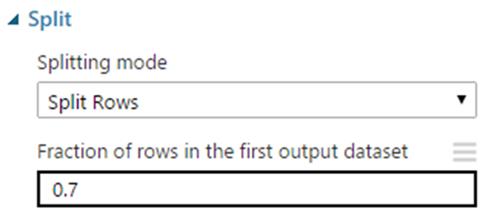
The ratio should be typed as a decimal number between 0 and 1 to represent the percentage of rows sent to the first output dataset.
For example, if you type 0.75 as the value, the dataset would be split by using a 75:25 ratio, with 75% of the rows sent to the first output dataset, and 25% sent to the second output dataset.
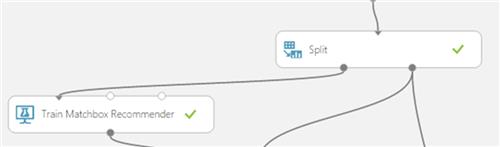
4. Add the Train Matchbox Recommender
The Train a recommendation model based on the Matchbox recommender engine. It has the ability to learn about people’s preferences from observing how they rate items such as movies, content, or other products.
This is where learning occurs.
5. Add the Score Matchbox Recommender
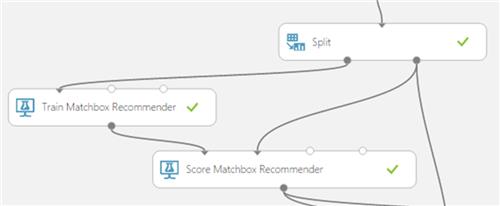
The Score Matchbox Recommender Scores predictions for a dataset using the Matchbox recommender.
It generates results based on a trained recommendation model
6. Add the Evaluate Recommender
It evaluates the accuracy of recommender model predictions
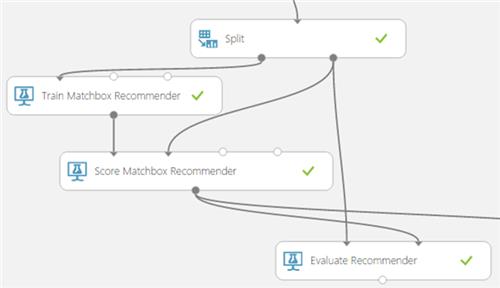
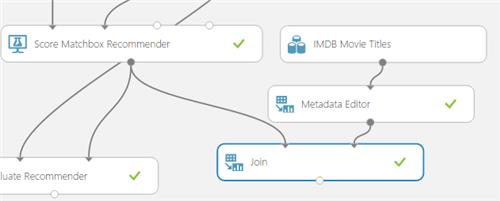
At this point in time, our solution is like below and we may run it by clucking on the Run button.
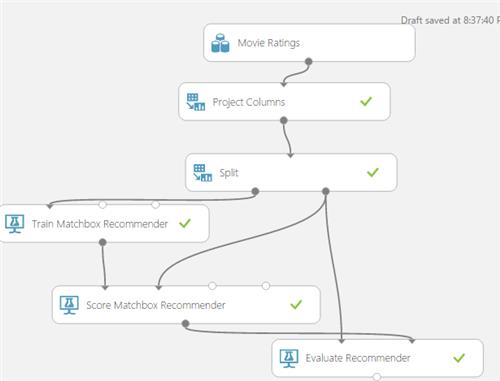
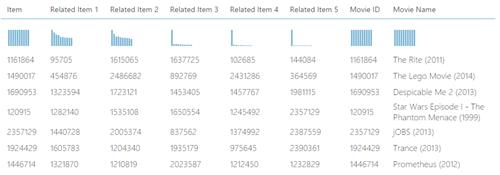
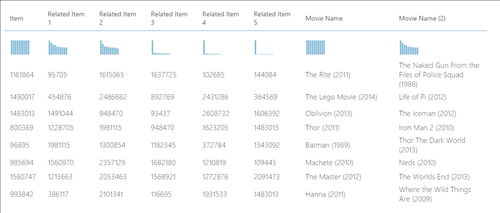
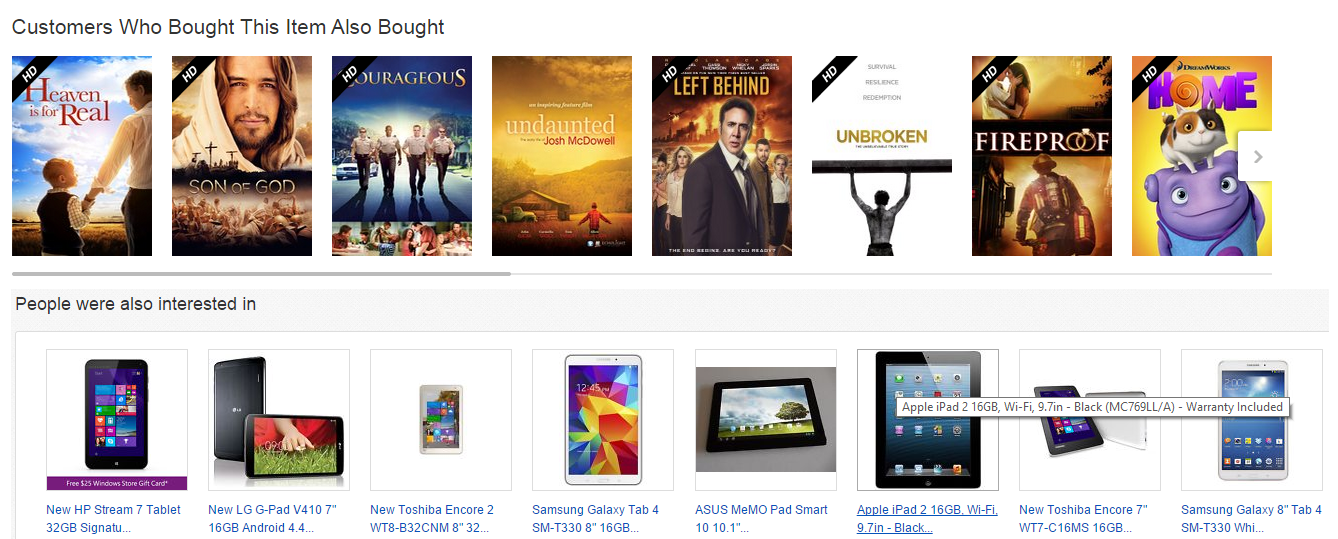
After its execution, if we click on the output of the Score Matchbox Recommender and click on visualize, we have all the movie IDs together with their respective “related” movies” as shown below.

However, this won’t be much useful for analysis purposes. What we want is to have the movie names instead of the movie IDs.
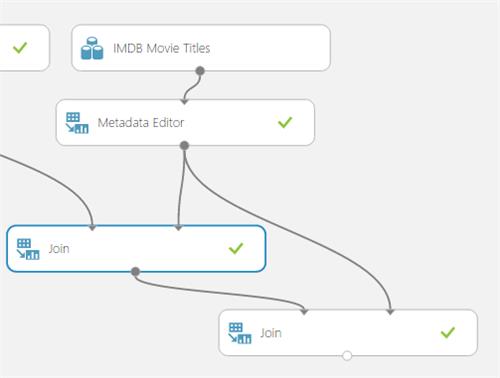
Fortunately, we can use the Join Operator. That’s what we shall do below.
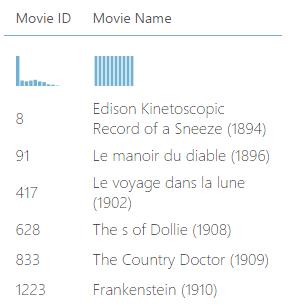
7. Add the IMDB Movie Title Sample
This sample has all the Movie Names and their respective Movie IDs.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}