Big Data Analytics using Microsoft Azure: Introduction
Introduction to Big Data
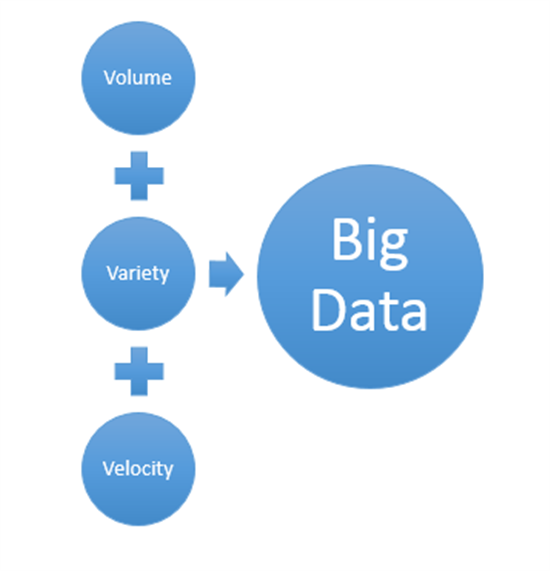
What is Big Data?
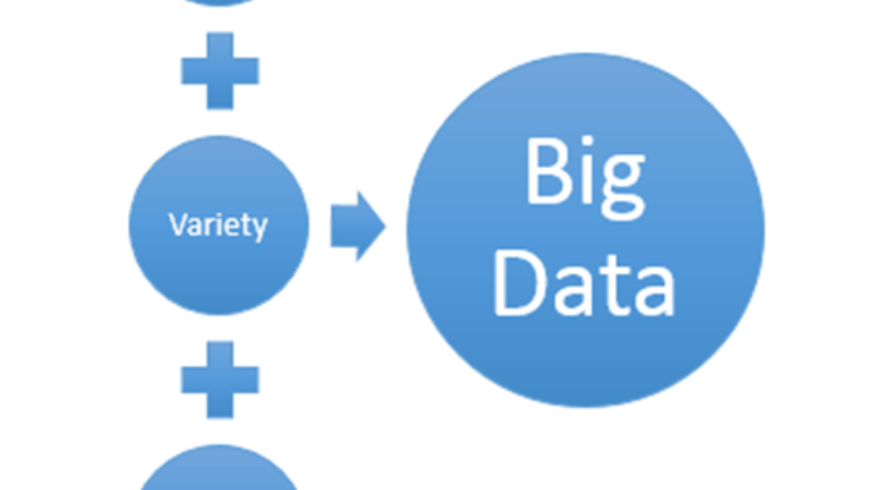
Big Data refers to data that is too large or complex for analysis in traditional databases because of factors such as the volume, variety and velocity of the data that needs to be analysed.
VolumeThe quantity of data that is generated is very high.
For Example, consider analyzing application logs, where new data generated each time a user does some action in the application. This may generate several lines per minute or even per second depending on the frequency the application is being used.
VarietyThe data that needs to be analysed is not standard, consisting of both structured and unstructured data.
One example of this can be the analysis of Social Media data consisting of emoticons, hash tags and texts in several languages.
VelocityThis is where data is being generated very frequently and at a very high pace. This is happening more and more often with the emergence of the Internet of Things where devices/sensors are generating data continuously.

What is Apache Hadoop?
Apache Hadoop is a framework that is mostly used to analyse Big Data.
It does distributed processing of large data sets where the data is split across clusters of computers using simple programming models.
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
What is MapReduce?
MapReduce is the application logic which splits the data for processing by different nodes in the Hadoop cluster.
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner.
The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system.
The framework also takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
MapReduce is done in the 3 steps below:
1. Source data is divided among data nodes
2. Map phase generates key/value pairs
3. Reduce phase aggregates values for each key

Introduction to Azure HDInsight
Azure HDInsight deploys and provisions Apache Hadoop clusters in the cloud, providing a software framework designed to manage, analyze, and report on big data.
The Hadoop core provides reliable data storage with the Hadoop Distributed File System (HDFS), and a simple MapReduce programming model to process and analyze, in parallel, the data stored in this distributed system.

Creating an HDInsight Cluster
To create and Azure HDInsight Cluster, open the Azure portal, click on New > Data Services > HDInsight.
The following options are available:
a. Hadoop is the default and native implementation of Apache Hadoop
b. HBase is an Apache open-source NoSQL database built on Hadoop that provides random access and strong consistency for large amounts of unstructured data.
c. Storm is a distributed, fault-tolerant, open-source computation system that allows you to process data in real time.
In this article, Hadoop cluster shall be used.

The next step is to add a cluster name, select the cluster size, add a password, select a storage and click on create HDInsight cluster.

Enable Remote Desktop on the Cluster
Once the cluster has been created, its jobs and contents can be viewed by remote connection.
To enable remote connection to the cluster, follow the steps below:
1. Click HDINSIGHT on the left pane. You will see a list of deployed HDInsight clusters.
2. Click the HDInsight cluster that you want to connect to.
3. From the top of the page, click CONFIGURATION.
4. From the bottom of the page, click ENABLE REMOTE.
In the Configure Remote Desktop wizard, enter a user name and password for the remote desktop. Note that the user name must be different from the one used to create the cluster (admin by default with the Quick Create option). Enter an expiration date in the EXPIRES ON box.

Accessing the Hadoop Cluster using Remote Desktop Connection
To connect to the cluster via Remote Desktop Connection, in the portal, select your cluster and go to configuration and click connect.
An RDP file will be downloaded which shall be used to connect to the cluster. Open the file, enter the required credentials and click connect.
Once the Remote Connection is established, double on Hadoop Command Line.
This command line tool shall be used to navigate through the Hadoop File System.

View files in root directoryOnce the command line is open, you may view all the files in the root folder.
The syntax to use is hadoop fs followed by the linux command used inside the Hadoop File System.
The command above will list all the files in the root folder.

When the cluster has been created, some sample files and data have already been included. To view them, navigate to the example folder.


View the sample data available

From the gutenberg folder, assume that MapReduce needs to be done on the file davinci.txt.
The file has lots of text which is actually an extract of an ebook.

Run MapReduce
To run a MapReduce job on the file davinci.txt, the following command is used.
The command consists of:
a. hadoop-mapreduce-examples.jar which is the compiled java code usedb. wordcount is the method called from the jar filec. /example/data/gutenberg/davinci.txt is the source datad. /example/results is the folder where the result shall be stored

View the result
The MapReduce job has been executed and the result saved in /example/results/.

Running MapReduce Jobs using PowerShell
Download and Install PowerShell
PowerShell can be download at the link here .

Connect PowerShell to a Microsoft Azure Account
Once PowerShell is installed, its time to connect it to your Azure Account.
The code below will open up the azure portal, ask for your credentials and download a file.
Key in the following command, together with the path to the file download above.
PowerShell is now connected to your Azure Account.

Upload Data
The script below will upload all the files from the your local folder to Azure storage. The source location should be entered in the variable $localFolder while the location to save the file on Azure should be in the variable $destFolder.
The script shall loop though all the files in the local folder and upload them to the destination folder.
The values of $storageAccountName and $containerName should be replaced by values that maps the Azure account being used.

Once the files have been uploaded, they may be viewed from the portal by going to the cluster > dashboard > linked Resources > Containers

Run the MapReduce
Once that data has been uploaded, it needs to be processed using MapReduce, and the script which creates a new MapReduce job definition.
The command New-AzureHDInsightMapReduceJobDefinition takes the following parameters:
1. JarFile “wasb:///example/jars/hadoop-mapreduce-examples.jar” : The location of the Jar file containing the MapReduce code
2. ClassName “wordcount” : The class to be used inside the Jar file.
3. Arguments “wasb:///UploadedData”, “wasb:///UploadedData/output” : Represents the Source and Destination folder respectively.
Once the definition of the job is created, the job is executed by the command Start-AzureHDInsightJob which takes as parameter the cluster name and the job definition.
The execution progress shall be displayed on the PowerShell console.

View the result
When the MapReduce completes, the output folder specified above shall be created and the result shall be stored in it.
From the Azure portal, navigate to the storage account > Container and notice that the folder “output” has been created.

Select the files and download them to view the results.

Conclusion & Next Steps
In the next article, we shall see how Hive can be used to execute SQL-Like queries against big data.
References
1. http://azure.microsoft.com/en-us/documentation/articles/hdinsight-hadoop-introduction/
2. http://hadoop.apache.org/
3. http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
4. http://azure.microsoft.com/en-us/documentation/articles/hdinsight-administer-use-management-portal/#connect-to-hdinsight-clusters-by-using-rdp

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}