Big Data Analytics using Microsoft Azure: Hive
Introduction
What is Appache Hive?
Hadoop is an open source implementation of Map Reduce which is widely used to store and process large amount of data in a distributed fashion.
Apache Hive is a data warehousing solution which is built over Hadoop. It is powered by HiveQL which is a declarative SQL language compiled directly into Map Reduce jobs which are executed over the underlying Hadoop architecture.
Apache Hive also allows the users to customize the HiveQL language and allows them to write queries which have custom Map Reduce code.
Prerequisite
Please read the article on Big Data Analytics using Microsoft Azure: Introduction for an introduction of Big Data, Hadoop, Azure HDInsight and some examples at how the Microsoft Azure platform can be used to solve big data problems.
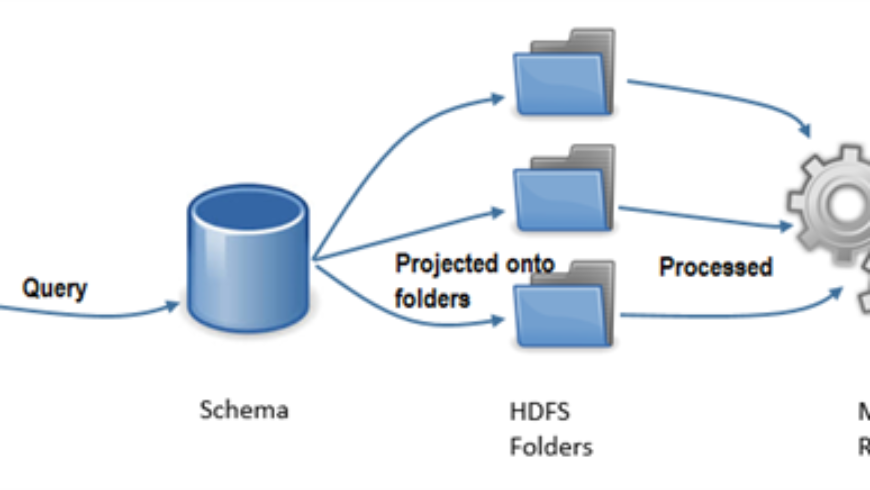
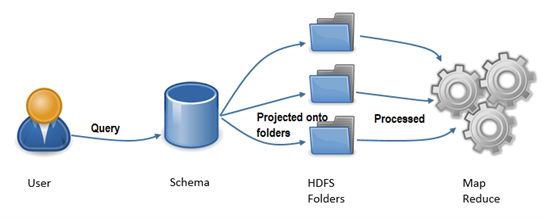
Schema on Read
Hive uses a metadata service that projects tabular schemas over HDFS folders.
This enables the contents of folders to be queried as tables, using SQL-like query semantics which are then converted to Map-Reduce Jobs.
That is, the tables are just meta data to represents the format in which data will be used. It is only when the queries will be executed that the data shall be projected onto the schema and processed using map reduced.

Creating Hive Tables
Use the CREATE TABLE HiveQL statement is used to create tables that project into the files to be used.
It defines a schema metadata to be projected onto data in a folder when the table is queried (not when it is created)
Two types of tables can be created:
1. Internal tables manage the lifetime of the underlying folders. Using Internal tables, If table is dropped all the file and contents shall be dropped.
a. No location specified when creating the table
when no location is specified, the contents will be stored at the default location which is, /hive/warehouse/table1 .
b. Table stored at a custom location during its creation.
Note that the table is still internal, so the folder is deleted when table is dropped
2. External tables are managed independently from folders
If the table id dropped, the table meta-data is deleted but all the data remains on the Azure Blob Store.
Loading Data into Hive Tables
1. Use the LOAD statement
Moves or copies files to the appropriate folder.
2. Use the INSERT statement
Inserts data from one table to another.
Querying Hive Tables
Query data using the SELECT statement
Hive translates the query into Map/Reduce jobs and applies the table schema to the underlying data files
Querying Hive from the Command Line
To query Hive using the Command Line, you first need to remote the server of Azure HDInsight. Follow this article to get the steps to do the remote connection.
In the example below, 2 tables shall be created, Raw Log and Clean Log.
Raw Log will be a staging table whereby data from a file will be loaded into.
Clean Log shall contain data from Raw Log that has been cleansed.
The Hive Variable
The SET command is used to view the Hive Variable.
It’s just an easier way to access Hive instead of typing the full path each time.

Open the Hive Environment
Hive Queries can only be executed inside the Hive Environment.
To open the Hive Environment, use the command below:

Once the Hive Environment has been accessed, now the file to be processed needs to be uploaded.
Below is the format of the Log File to be used in this example.

Create the Internal table
The main use of the internal table in this example is to act as a staging table to cleanse data to load in the CleanLogtable.
Since no file location is specified, it shall be stored at the default location, which is, /hive/hive/warehouse.

Create the External table
This is the table where the cleansed data will be stored and queried.

View the Hive Tables
To view the Hive tables, the SHOW TABLES command can be used.

Load data into the staging table
To load the raw data from the folder into the staging table, the LOAD DATA command should be used.

After the loading completes, you may test the schema by doing a select from the table rawlog.

Move data from the staging table to the data table
The command below will load data from the staging table into the data table while excluding rows having # at beginning

Generates Map Reduce and Make Analysis
Now that the data is cleansed, it can now be queried using HiveQL and this is where Map Reduce code will be generated and applied.
In the example below, the number of page hits per IP per date is calculated.


Querying Hive from PowerShell
Azure PowerShell provides cmdlets that allow you to remotely run Hive queries on HDInsight. Internally, this is accomplished by using REST calls to WebHCat (formerly
called Templeton) running on the HDInsight cluster.
PowerShell cmdlets for Hive
The following cmdlets are used when running Hive queries in a remote HDInsight cluster:
1. Add-AzureAccount: Authenticates Azure PowerShell to your Azure subscription
2. New-AzureHDInsightHiveJobDefinition: Creates a new job definition by using the specified HiveQL statements
3. Start-AzureHDInsightJob: Sends the job definition to HDInsight, starts the job, and returns a job object that can be used to check the status of the job
4. Wait-AzureHDInsightJob: Uses the job object to check the status of the job. It will wait until the job completes or the wait time is exceeded.
5. Get-AzureHDInsightJobOutput: Used to retrieve the output of the job
6. Invoke-Hive: Used to run HiveQL statements. This will block the query completes, then returns the results
7. Use-AzureHDInsightCluster: Sets the current cluster to use for the Invoke-Hive command
Executing HiveQL Queries
In the following example, a new table webactivity shall be created containing aggregated data from table cleanlog(created in the previous example)
The HiveQL to be used is as follows:
1. Drop the table webactivity if it exists
2. Create external table webactivity
3. Aggregate data from table cleanlog and insert into table webactivity
Using AzureHDInsightHiveJobDefinition Cmdlet
Below are the PowerShell scripts to execute the queries explained above.
1. Specify the cluster into which to do the queries
2. The HiveQL Queries
3. Define the hive job for the Azure HDInsight service.
4. Starts the Azure HDInsight job in cluster chervinehadoop
5. Awaits the completion or failure of the HDInsight job and shows its progress.
6. Retrieves the log output for a job



Using the Invoke-Hive Cmdlet
Once the table has been created and populated, It can then be queries.
The easiest way to execute Hive Queries is to use the Invoke-Hive cmdlet.
1. Define the cluster and the query to be used.
2. Select Azure HDInsight cluster that will be used by the Invoke-Hive cmdlet for job submission.
3. Submits Hive queries to the HDInsight cluster

Querying Hive from the Azure Portal
So far, the article focused on the technical parts, how Hive works and how to automate the process using PowerShell.
Using the command line and PowerShell is mostly intended to developers and is not user friendly.
Hopefully, Hive Queries can also be executed from the portal which makes it a lot more easier to use.
To use this feature, go to the HDInsight Homepage on Azure and click on Query Console.

Once you are logged in, you will be routed to the the Microsoft Azure HDInsight Query Console Homepage.
From here, you can view some sample Queries from the gallery, Write your own queries using the Hive editor, View the jobs execution history and browse the files in the
cluster.
In this example, the same queries as in the PowerShell example shall be written but from the Azure Portal.
To do so, Click on the Hive Editor and paste in the queries.

Once you click on submit, the processing will start and you will be able to monitor the status from the Job Session Pane.

When it completes, the file will be saved in the blob at the path specified.

Conclusion & Next Steps
The main advantages of Hive is that its very easy to use and quicker to develop Big Data solutions as HiveQL is very similar to SQL but translates to Map Reduce codes behind the scenes despite being transparent to the user. Moreover, the use of external tables which make it possible to process data without actually storing in HDFS and keeps the data even if the cluster is deleted is also a very good benefit in terms of cost.
In the next article, more on the practical example of Big Data by analyzing Twitter Feeds shall be discussed.
References
1. http://azure.microsoft.com/en-in/documentation/articles/hdinsight-use-hive/
2. http://azure.microsoft.com/en-in/documentation/articles/hdinsight-hadoop-use-hive-powershell/
3. https://msdn.microsoft.com/en-us/library/dn593749.aspx
4. https://msdn.microsoft.com/en-us/library/dn593743.aspx
5. https://msdn.microsoft.com/en-us/library/dn593748.aspx
6. https://msdn.microsoft.com/en-us/library/dn593738.aspx


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}